.svg)

At Rivanna, we’re building AI for private markets due diligence, and we believe that accuracy and auditability are essential in due diligence applications. In other words, for AI to reason over data effectively, it must first retrieve the correct data.
As private market investors navigate the landscape of AI tooling for investment use cases, they are often faced with the challenge of evaluating specialized tools such as Rivanna against general purpose platforms such as ChatGPT and Claude.
To help firms better evaluate the different options, we tested Rivanna against ChatGPT and Claude on their ability to accurately retrieve data from an example data room of ~500 documents.
The results found that Rivanna significantly outperformed on both accuracy and speed.
In the content below, we walk you through the drivers of these results, the limitations of general purpose AI platforms, and Rivanna’s approach to building accurate AI that firms can trust for their most critical decisions.
The Experiment
Data rooms are the backbone of private markets due diligence, but finding the relevant data within them is difficult.
This is because data rooms contain massive amounts of documents, folder organization is often poor, file names unclear (“Final_v3_updated.xlsx”), scanned documents are prevalent, and critical financial data is often located in large Excel workbooks. Important context may be buried in appendices, footnotes, or the last sheet of an Excel file.
The complexity of data involved in due diligence therefore presents a challenge for AI.
To test how different AI systems handle this challenge, we assembled a representative data room containing 496 documents about an example publicly traded company, including financial statements, legal agreements, operational reports, scanned PDFs, and complex Excel models.
We then created a set of 65 fact-based questions designed to evaluate those systems’ ability to accurately retrieve data embedded within the dataroom.
The AI systems tested were
- Rivanna, using Sonnet 4.6 as the main LLM
- ChatGPT Projects (executed with vector store), using GPT-5
- ChatGPT with a Sharepoint Connector, using GPT-5
- Claude Cowork, using Sonnet 4.6
Results
Rivanna significantly outperformed the ChatGPT and Claude configurations, both on accuracy and speed.
In terms of accuracy, Rivanna scored 95% while ChatGPT and Claude CoWork scored within a range of 60 to 72%.
Dataroom Data Retrieval Accuracy

In terms of latency, Rivanna averaged 15 seconds to answer each question. ChatGPT Projects averaged 38 seconds, while ChatGPT plus SharePoint and Claude CoWork both averaged above 95 seconds per question.
Dataroom Data Retrieval Average Response Speed

These results indicate that not only did Rivanna answer more questions correctly, it also did so significantly more quickly than ChatGPT and Claude.
Where ChatGPT and Claude Fall Short
ChatGPT and Claude underperformed Rivanna for two key reasons, both rooted in the fact that they do not have a document preprocessing architecture.
- ChatGPT and Claude lack the ability to perform semantic searches across an entire corpus of files, severely limiting their ability to locate relevant information within large and complex document repositories.
- ChatGPT and Claude also lack the tooling to read challenging file formats prevalent in data rooms, such as scanned documents and large Excel files.
These platforms must rely on the limited search tools available through terminal commands or data connectors from third party document management systems such as SharePoint.
To compensate, ChatGPT and Claude use brute-force iteration through documents that appear closely related to the user’s query, but this approach is both low-resolution and time-intensive.
The end result is that ChatGPT and Claude are limited in their ability to accurately retrieve data from large document corpuses, which increases the risk of hallucination.
To illustrate, consider two questions from our benchmark:
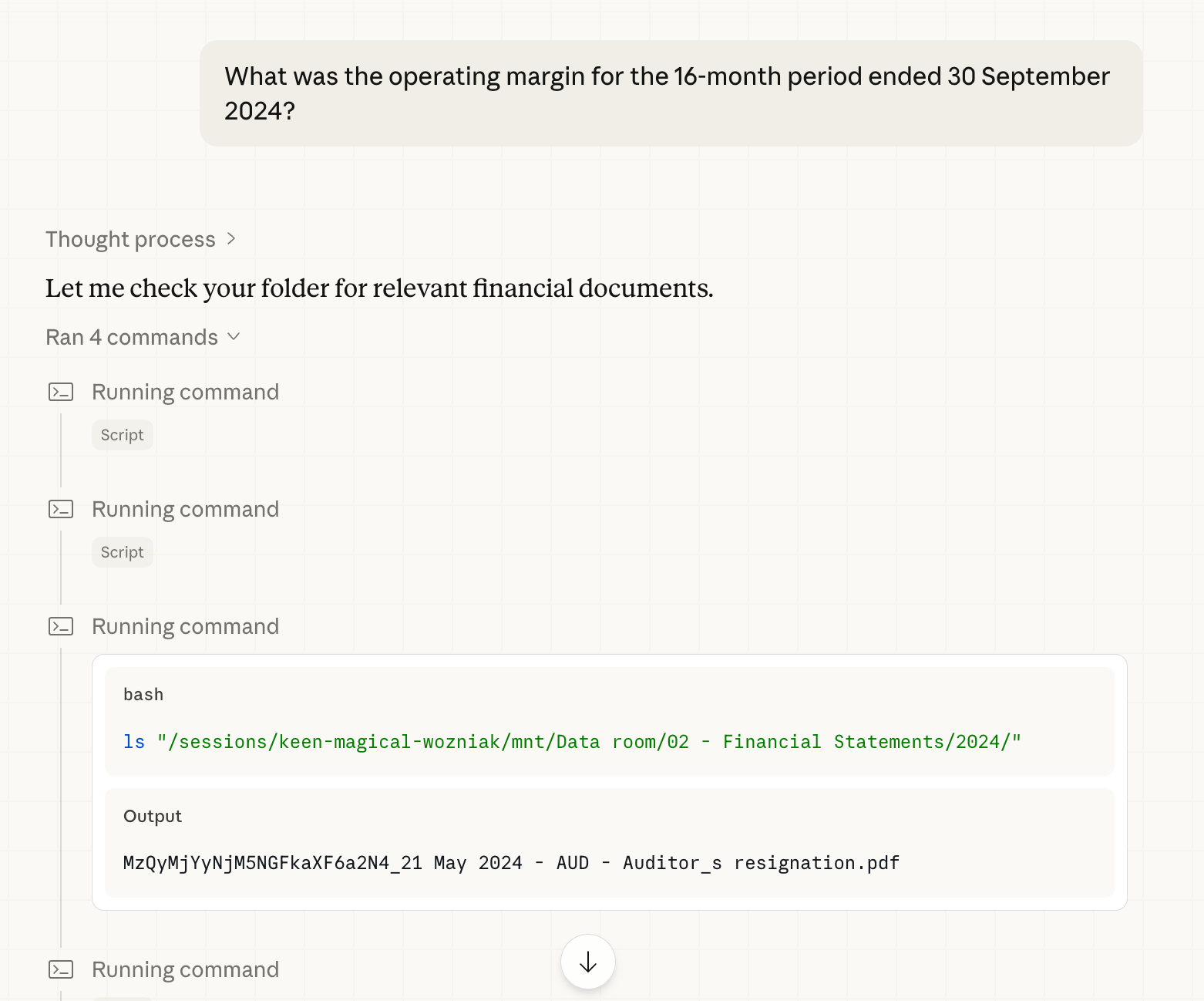
Example 1: What was the operating margin for the 16-month period ended 30 September 2024?
Because Claude Cowork lacked the ability to perform semantic search across an entire data room, it relied largely on file-name interpretation and sequential document review. This method fares poorly when documents are named poorly and/or numerous, which is commonly the case in due diligence.
To execute the query, Claude first searched for “operating margin” across file names in the data room. It then sequentially opened and read several documents that appeared relevant, eventually navigating to a PDF of the annual financials. After a few iterations, Claude located some directionally relevant snippets but not the actual relevant source snippet.
Claude calculated an operating margin of 5.2% based on the incomplete data it found. The actual operating margin stated in the report, however, was (4.5%).
Example 2: What was the quantum of FY23 strategic impact investments?
Like Claude, ChatGPT also does not preprocess documents and is unable to perform semantic search.
ChatGPT accesses the document data through a SharePoint connector, but the search tools exposed by the SharePoint connector are shallow. The SharePoint connector exposes a single search tool that is only capable of performing keyword search and without returning content snippets.
Using the SharePoint connector, ChatGPT searched for “strategic impact investments FY23” and got zero results.
ChatGPT then executed over a dozen tool calls navigating folder structures and listing directory contents, trying to “manually” locate the right document through brute force.
ChatGPT never found the answer (£5m), eventually responding: "Not found in the SharePoint docs I can access." The information was there, but its search just wasn't powerful enough to surface it.
Why Document Pre-Processing is Critical for Due Diligence
The limitations of ChatGPT and Claude lie not in their level of intelligence, but in their inability to effectively find and interact with the data.
To address this limitation, Rivanna preprocesses uploaded user documents at ingestion into searchable chunks, which enriches the underlying data and enables the AI system to perform more sophisticated data retrieval using a richer set of tools.
This architecture enables Rivanna to find data that general purpose LLM systems would have missed, and do so more quickly.
For example, Rivanna can perform multiple kinds of searches (including semantic, keyword, and filename) across the entire dataroom, search more narrowly on specific documents or folders, navigate through Excel spreadsheets, and read specific snippets of a given file.
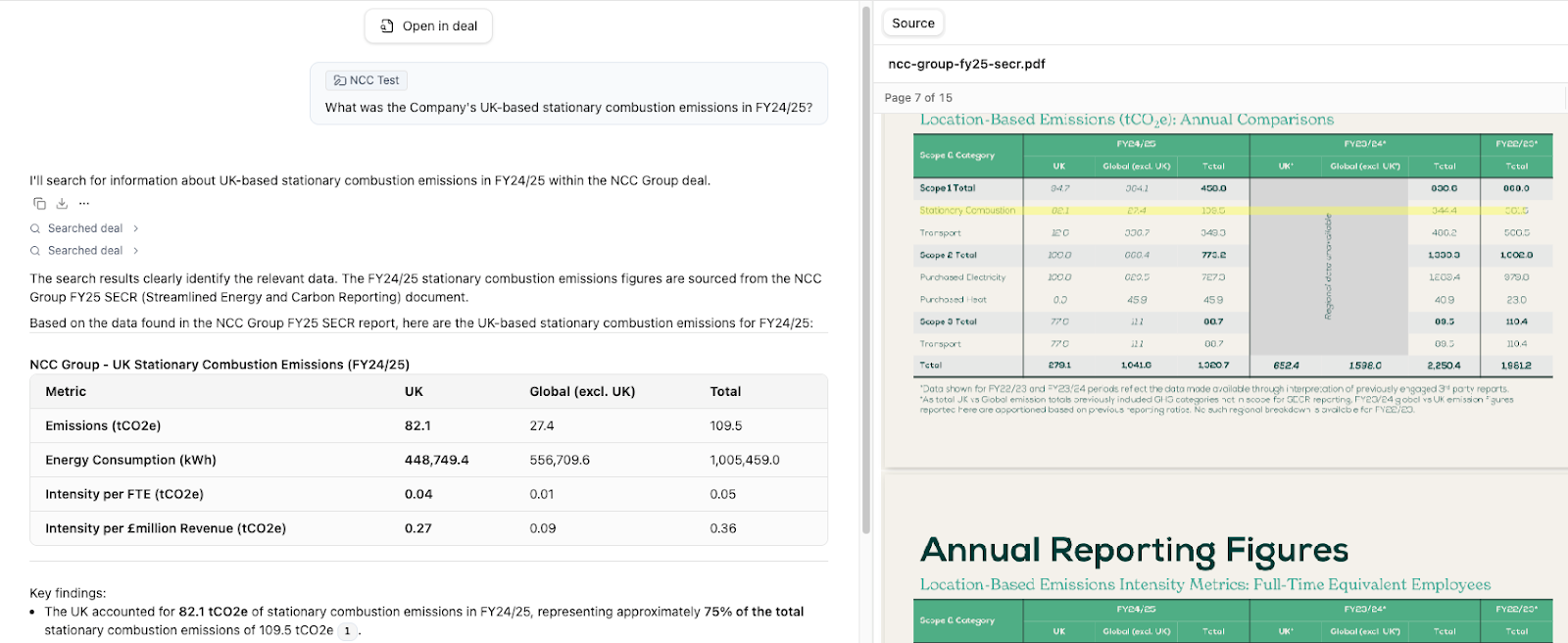
Importantly, Rivanna’s architecture also enables direct, granular citations that are unavailable in ChatGPT or Claude. This is one of the most important and popular aspects of our platform, as seamless auditability is critical for high-stakes private equity workflows.
Architecting a system to perform robust preprocessing is challenging and highly costly, and is only “worth it” if the system’s main use case relies heavily on accurate data retrieval from large and messy document corpuses. Due to their general-purpose and enormous user base, ChatGPT and Claude have forgone specialized preprocessing and decided to use more “general” methods for data retrieval, which are inherently weaker.
The Bottom Line
The AI models being developed by the foundational labs are getting more intelligent every day, and we are excited about the opportunities that this growing intelligence enables for private markets due diligence.
However, intelligence is not all you need in real-world applications.
Finding the right data is just as important, and it requires specialized infrastructure: deep document processing, powerful search capabilities, and tools that allow models to interact with data the way analysts do.
Rivanna is built specifically to bridge accurate data retrieval with frontier model intelligence, providing our customers across the private markets with AI that they can trust for their most critical decisions.
The full technical report will be released soon at www.rivanna.ai. To get in contact with Rivanna’s team, please reach out to contact@rivanna.ai.